Situation
Georgian verbs are famously complex, featuring a multi-slot morphological system where a single word form can encode subject, object, and version markers. Manually analyzing these forms is time-consuming, and standard text-based dictionaries fail to illustrate how individual morphemes shift across different grammatical categories.
Task
I was responsible for building a technical bridge between raw linguistic data and human-readable analysis:
- ML Segmentation: Develop a model to automatically split verb forms into constituent parts (e.g., ga-v-aket-eb-di).
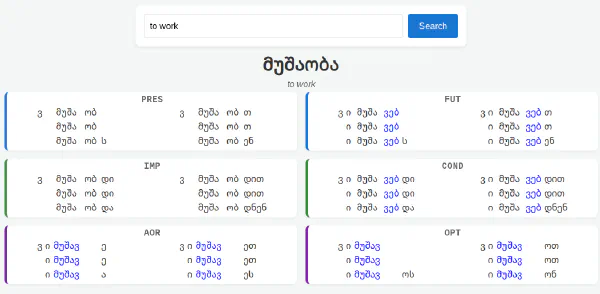
- Interactive Visualization: Build a web-based dashboard to align and compare these segments visually for researchers and students.
Action
I approached this as a two-stage engineering problem:
1. The Segmentation Model (Back-End)
I implemented a Conditional Random Field (CRF) model using sklearn-crfsuite to treat morphological segmentation as a sequence labeling task.
- State Logic: To handle Georgian orthography, I used a three-state logic—I (Inside), S (Single), and N (Null)—to account for the “empty slots” common in Kartvelian verb structures.
- Accuracy: The model was trained on a dataset of over 13,000 forms, learning to identify root variations and prefix/suffix changes across different screeves.
2. The Morphological Dashboard (Front-End)
I built a reactive interface using Vue.js to display the model’s output in a meaningful way.
- Synchronized Alignment: Using CSS Grid, I engineered a master table that vertically aligns every grammatical slot, ensuring that roots and preverbs stay perfectly stacked across an entire paradigm.
- Interactive Highlighting: I added a “hover-sync” feature where interacting with a specific morpheme (like a versionizer) highlights its counterparts throughout the chart, making subtle linguistic shifts instantly visible.
Result
- High-Precision Analysis: The model achieved ~98% word-level accuracy on complex verb forms.
- Visual Clarity: The dashboard successfully isolates stem developments and thematic changes that are traditionally difficult to trace in flat text.
- Scalable Infrastructure: This system allows for the rapid processing of massive verb databases, turning raw strings into structured, educational datasets.